I finally switched to Android when, in 2020, my old iPhone 5S forcibly and needlessly bit the dust at the behest of the Apple Corporation’s planned obsolesce policy.
While in the process of moving back to Germany during the COVID-19 pandemic, my temporary housing was through a shall-not-be-named platform, whose app no longer ran on the iOS version the 5S had been limited to. In order to adhere to Germany’s (very reasonably) strict quarantine policy for new arrivals at the time, I realized I had no choice but to upgrade, seeing as making it expeditiously to my lodging was a matter of public health, and the app was the only reasonable way of communicating about my arrival with my landlady.
My logic behind making the switch to Android was, “oh **** I need a phone that runs a newer OS” and “my budget is about 0 dollars”. In the end, I ended up with a Moto Power G (2020), which was the cheapest conventional smartphone I could find that was compatible with my current cellular plan. The fact that it was an Android was almost an after-fact, though my deep frustration with a certain company’s proclivity towards deceitful dealings with aging products did play some role, I’d like to think. While, yes, I will admit that the Moto G did seem to handle daily life better than the 5S (no, it did not lose all my texts now and then), by the time I’d had it for about two years it fared worse than the 5S did after four or five. Which, in retrospect, did make some sense — I mean, I did buy the cheapest smartphone I could.
The idea that I had a two-year-old smartphone that was no longer functional drove me crazy though. Sure, there was the financial kicker; at this point, the Moto G was probably as expensive as if I’d just bought an iPhone and kept it for an extra year or two, which I suspect it could have probably handled (especially after those class-action lawsuits Apple ended up in). But there was also the environmental impact — I mean, good gosh, was I supposed to just dispose of a ridiculously resource-draining device after a mere two years of use? Incidentally, this coincided with a research project I was conducting about dumbphones, and the desires of many dumbphone users to keep devices that just worked for a long time. Better for the wallet, better for the environment.
This led me down a rabbit hole of modular phones, most of which exist only in popular form with a “X Company Shuts Down Development of Planned Modular Phone”. Failing that, I figured the next best thing was a phone that would at least keep current (receive regular OS and security updates) for some time (i.e., more than two years). So obviously Apple devices were out. While Fairphone was the most reasonable dealer I could find, reviews by mainland-US users indicated that the EU-intended device barely functioned, and rarely reliably, if at all, stateside. After much searching, I realized one option would be to buy an older flagship device (easier on the wallet, and somewhat environmentally less bad?) and flash it with a mobile OS more dedicated to longer-lasting support. Which resulted in my purchasing a Google Pixel 4a (via a refurbished tech site), a device which was, approximately, ironically, the same age as my malfunctioning Moto G.
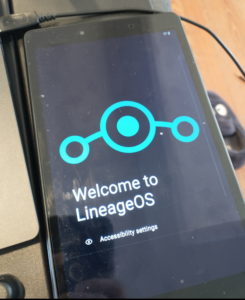
I knew I was making a few concessions to modern ease when I switched to Lineage as a “daily driver”. First, Google would treat the bootloader as being tampered with, and some apps might be incompatible. I’d read ahead of time that many financial apps, for example, would disable sign in with finger-print ID, which was fine with me, since I’d quit using biometric login features since the 5S.
On the plus side, it meant that I could change my relationship with Google, which was inflexible on the stock Android the Pixel 4a ran by default. Instead, I admitted to my unhealthy reliance on Google Maps (particularly when traveling) and added the Google Apps for Lineage OS (GAPPS) package. When I’m not traveling or anticipating getting lost, which is, I admit, a fairly imperfect solution, since I tend to get lost at unexpected times. Maybe the secret to personal privacy is perfecting one’s sense of location?
I’m now about five or six months into daily life with the mostly-de-Googled, Lineage-running Pixel 4a. On the whole, I’m pleased with my experience. The actual experience of flashing Lineage to the device was much easier than with my Samsung tablet, and took about 30 minutes (though, at this point, I have some experience mucking around in adb).
As for the experience of using Lineage, there are quirks, most often with the default phone application. I suppose I could just download the Google one. The Google Wallet feature doesn’t work with any financial details (I can still store thinks like plane e-tickets, but not credit cards). I feel like this is probably for the best, considering that lodging my credit card in my phone is just one more case of data seepage, but would be an issue for more regular users of contactless payment. In general, the Lineage default app versions sometimes just don’t work quite right, which isn’t something I can really complain about, given that Lineage doesn’t have the kind of financial and organization backing that Google’s Android OS teams have. Further, a 1-3% latency with basic applications probably helps me use my device less, since things are not quite as quick and easy as they are with flagship devices. Or maybe this is psychological. Who cares, I think my screentime is slightly down, which is all I can ask for.
As far as hardware, the battery life is much better with Lineage than it was for the short time I ran out-of-the-box Google Android. The device I bought has been well used, and the battery life is definitely strained to last a whole day without a partial recharge, which might require use of an external battery pack for someone who doesn’t have a desk job. I’m pleased the device still has a headphone jack, so I can make use of the dozens of old Apple corded headphones that have been passed on to me by the rest of my family members, who have upgraded to jack-less iPhone versions. As someone who frequently listens to radio and music, having a dozen or so pairs of headphones makes it a whole lot easier to always have a pair within reach, something I definitely can’t say about bluetooth devices (did I mention the cord also means there’s no battery life to deal with? Wild.)
Somewhere between hardware and software is my main gripe: dual SIM support. While back in Germany this summer, I needed to maintain both my US number and my German one, with easy access to both. Thanks to a thankfully well-timed introduction of Edeka Smart’s e-SIM option, I used my Mint Mobile (US) plan SIM in the physical SIM slot, with the Edeka as the e-SIM. My voicemail has never recovered, which, honestly, is fine since in the five or so months I’ve been using the device, I think I’ve gotten about four voicemails total. Would this be an issue for perhaps an older user more accustomed to actually speaking with people on the phone? Yes, absolutely. I’m also aware that the 4a is relatively unsophisticated in it’s dual SIM capabilities and newer versions of the Pixel might handle it better.
On the whole, I like having my phone be my phone and not an advertising portal I carry around with me. Is it still a little bit of an advertising portal? Of course, but I feel like I’m able to make reasonable trade offs in my exposure to data collection — for example, figuring out how to navigate around a new city is worth a few breadcrumbs of location data. Do I use a different Google account with each Google app that I do have installed? Sure. Does it help minimize my exposure? Probably not?
On the whole, I feel like this is one of the more reasonable options for a privacy-respecting smartphone. While it certainty requires an intermediate level of tech savvy, at least in getting set up, I think it could be reasonably used as a “daily driver” for anyone used to contemporary smartphones and willing to make some small sacrifices to protect their personal information, while still getting many of the benefits of a smartphone.